OpenAI押注的「1X」训出专用世界模型,首证机器人Scaling Law
OpenAI押注的「1X」训出专用世界模型,首证机器人Scaling Law机器人能认出镜子中的自己吗?目前来看,依然做不到。
来自主题: AI资讯
6991 点击 2024-09-19 11:04
 搜索
搜索
机器人能认出镜子中的自己吗?目前来看,依然做不到。
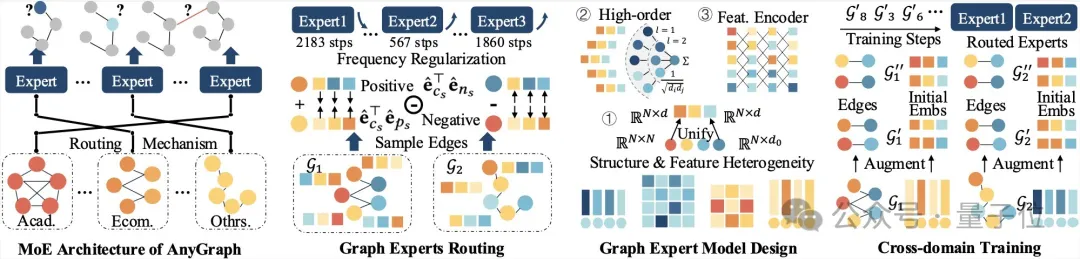
新型图基础模型来了—— AnyGraph,基于图混合专家(MoE)架构,专门为实现图模型跨场景泛化而生。

OpenAI用o1开启推理算力Scaling Law,能走多远?
好家伙,OpenAI 终于上新了!

最近的公司会议上,奥特曼向全体员工承认,明年OpenAI或将摆脱非营利组织结构。o1的问世,直接诞生了新的Scaling Law,更是在医疗性能上表现出色。不过,o1能拯救OpenAI 1500亿美元的估值,和今年50亿美元的亏损吗?
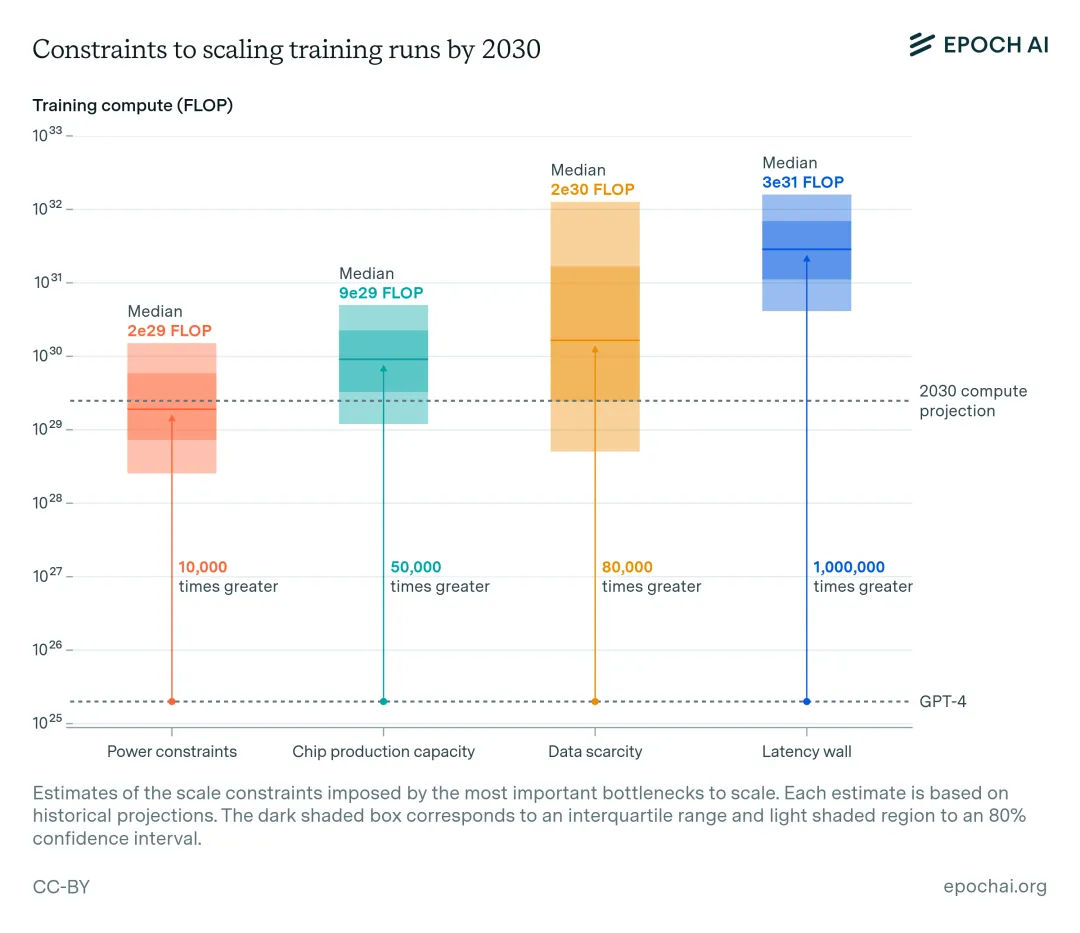
近年来,人工智能模型的能力显著提高。其中,计算资源的增长占了人工智能性能提升的很大一部分。规模化带来的持续且可预测的提升促使人工智能实验室积极扩大训练规模,训练计算以每年约 4 倍的速度增长。
蹭下热度谈谈 OpenAI o1 的价值意义及 RL 的 Scaling law。

近段时间,AI 编程工具 Cursor 的风头可说是一时无两,其表现卓越、性能强大。近日,Cursor 一位重要研究者参与的一篇相关论文发布了,其中提出了一种方法,可通过搜索自然语言的规划来提升 Claude 3.5 Sonnet 等 LLM 的代码生成能力。

不必增加模型参数,计算资源相同,小模型性能超过比它大14倍的模型!

大模型时代,有个大家普遍焦虑的问题:如何落地?往哪落地?